Duplicate content filtering process in Google Search
There are many excellent and comprehensive resources on duplicate content topic, and so if it’s quite new to you, I’d recommend to check this Moz article firstly. Also you may refer to one of the Google’s answers on the topic. If you’ve got interested in this topic and/or seek for more advanced information, I’d highly recommend reviewing all of the Bill Slawski posts on duplicate content topic based on patents granted to Google.
Duplicate content penalty is a myth
Discussion on “duplicate content penalties” started long time ago, and Google constantly denied existance of such (e.g. they tried to “put it question in bed once and for all” back in 2008, still unsuccesfully). Google spokesmen including Matt Cutts, John Mueller, Gary Illyes and others keep telling us that having duplicate content won’t hurt our website(s) unless it’s spammy (as far as I know, no one elaborated on spammy duplicate content this aspect so far). And that Google is really good at filtering such content and generally we don’t have to worry about it at all.
But why do people keep asking those questions? The answer relies in ability to distinguish between concepts. First up, usually people do not properly understand what “duplicate content” really is in the context of SEO. Some actual Google penalties look very similar, like the ones targeting content scraping activities or having thin content on-site. But these do not have anything in common with only having multiple URLs with the same content (which is the essential of duplicate content issues). Still some authors sometimes cannot distinguish between those, errors occur and myths nurture.
The second reason suggests that usually people do not distinguish between penalty and a filter. Duplicate content is usually referred to as penalty because it does act similarly to it (e.g. it will not rank duplicate search results unless a searcher clicks on the link at the bottom showing “display search results similar to the pages shown above”).
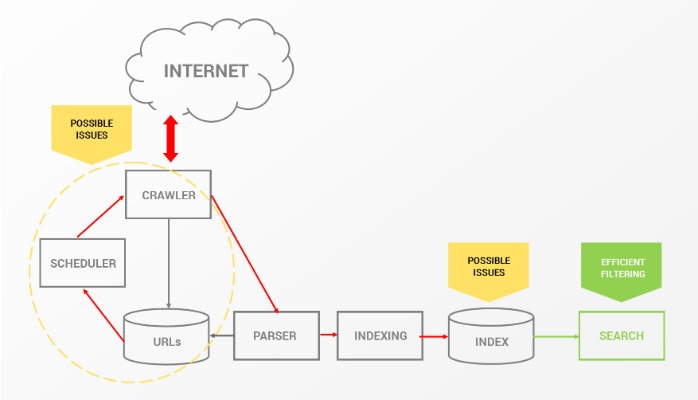
ranking != (crawling | indexing)
Third reason – many do not properly understand that crawling, indexing and ranking are three different processes influencing each other at some point and so they are dependent, but very different. Still many people are confused and use crawling and indexing terms interchangeably, others usually forget about ranking being different from indexing.
Also, some people are almost sure that duplicate content is one of the Google Panda’s usual targets on-site. Sadly, it’s not. One should keep in mind that duplicate content isn’t even related to Google Panda penalty. As Google’s John Mueller puts it, “Panda and duplicate content are two separate and independent things”.
And the last, but not the least – Google’s official statements does play a minor role here as well. Let’s take this one originally published on May 27, 2013 as an example:
When talking about penalties, Google always include a general statement about the intent to manipulate their rankings and deceive their users. As we can clearly see, this statement is very broad and it really fits almost everywhere, and it’s just fine. But another side of the coin suggests that using it right after such a “virgin” things like printer optimised versions of the articles isn’t that good idea as well. And this is how myths are sparked and nurtured by Google itself. Later they will be constantly asked whenether they really won’t apply “duplicate content penalty” because of printer optimised pages being indexed.
In Part 2 I will seek the answers to the question “where duplicate content really impacts visibility in Google Search” and provide some recommendations regarding this common issue.